
本人前段时间准备做个TIN三角网的程序,思想是是分割合并法,分割的同时建立平衡二叉树,然后子树建三角网并相互合并,再向上加入父亲的点集。由于我对.net语言熟点,就准备用c#语言实现。但是不知从那听过当建立的类型只想用来存储数据时,最好是用结构即值类型,用类影响性能。想想我先建立二叉树的节点,只需要一个点集集合和左右孩子节点的指针,用c++表示如下:
 struct Node { char c; Node* lChind; Node* rChild; }
struct Node { char c; Node* lChind; Node* rChild; }C++等指针性语言很容易建立这种结构,但是c#呢,这就比较麻烦了。c#等非指针性语言不直接支持指针类型,值类型之间赋值时会进行值的复制,只有在函数参数有关键字ref或out时才又引用的功能,怎样才能方便的实现值类型的指针功能呢。查资料知道c#支持unsafe关键字,这里就顺便总结一下.net的这方面的相关知识。这里先给个上面结构的c#实现方法:
unsafe struct Node { public char c; Node* lChild; Node* rChild; public Node(char value_ch) { c = value_ch; lChild = null; rChild = null; } public Node* LChild { get { return lChild; } set { lChild = value; } } public Node* RChild { get { return rChild; } set { rChild = value; } } public override string ToString() { string s = "值为:" + c; if (lChild != null) s += "," + "左孩子节点值为:" + lChild->c; if(rChild!=null) s += "," + "右孩子节点值为:" + rChild->c; return s; } } unsafe关键字支持以下的用法:
1.定义不安全类(unsafe class class_name{})
2定义类的不安全字段
3.定义不安全结构(unsafe struct{})。上面定义的那个结构就是个不安全结构。
4定义不安全方法,不管该方法是静态方法,虚方法,还是实例方法。
5定义不安全代码段(....safe code...unsafe{....不安全代码段...}....safe code...)
大家都知道.net平台支持垃圾收集功能,它提供了一个垃圾收集器。c#的类型总分为值类型和引用类型,垃圾收集器负责释放引用类型(准确的说是托管类型),所占的内存这很大程度上解决了c,c++等语言的内存泄露和重写问题。.NET平台的内存管理系统将值类型分配在堆栈上,分配时从高地址往低地址分配;引用类型则分配在堆上,分配时从低地址往高地址分配。下面定义的代码段说明了这个问题:
unsafe { int x, y, z; byte m=199; int n=200; x = 5; y = 10; z = 15; int* _p = &x; Console.WriteLine("x的地址为{0}",(uint)_p); Console.WriteLine("_p的地址为{0})",(uint)&_p); _p--; Console.WriteLine("y的地址为{0},_p的值为{1}",(uint)&y,(uint)_p); _p--; Console.WriteLine("z的地址为{0},_p的值为{1}", (uint)&z, (uint)_p); _p--; Console.WriteLine("m的地址为{0},_p的值为{1}", (uint)&m, (uint)_p); _p--; Console.WriteLine("n的地址为{0},_p的值为{1}", (uint)&n, (uint)_p); }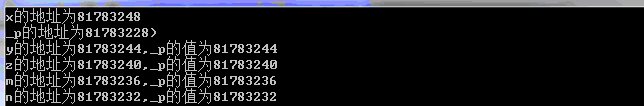
这里定义了x,y,z,m,n五个变量,还有一个整型的指针变量_p。接着输出它们的地址。从运行结果(这里我采用是十进制表示地址)我们可以看到这六个变量的地址依次降低,每个变量占四个字节的内存(int存储在32位处理器堆栈的连续空间上,并不是所有数据类型在堆栈上都是连续分配)。指针本质上也是一个整数,只是这个整数表示的是内存中的一个地址(在32为系统上是0~40亿),我们可以使用uint来对地址进行整数化。同时这里还涉及了一个指针的运算,指针_p首先指向x,然后减1(实际减了sizeof(数据类型)),前面我们说过内存分配在堆栈中是从高到底分配的,这时指针就指向了y,从结果可以看到y的地址和_p的值一样;如果我们将_p加1即指向内存81783252,会发生什么情况呢?谁也不知道会发生什么事情,如果我们给这个内存赋值,可能会重写被别的程序使用的这块内存,也可能是一个空内存的简单存值而已。上面还有个问题,m变量是字节类型的,理论上是占一个字节内存,这里为什么占四个字节内存(81783236~81783232)呢?原因是32位处理器最擅长于4字节的内存块中获取数据,这种机器上的内存会划分为4字节的块,为了下次分配时堆栈指针指向的是一个4字节内存块的开始处,所以.net决定在堆栈上分配内存时分配的大小为4的倍数(这里我也不是太清楚,我也是一个在校初学者,各位可不在此深入追究),故为byte类型分配了4字节的空间。当出了这些变量的作用域时,堆栈指针的值会依次增加,这相当于删除了这些局部变量。
引用类型则不是这样。引用类型的变量(指针)依旧存储在堆栈上,占领的空间为4字节,实际对象则保存在堆上,引用变量的删除和它所引用的对象的删除不是同步进行的,这会导致堆上的内存空洞的问题。堆里面保存了很多对象,垃圾收集器会维护这些对象的相关信息,如对象引用数,内存地址等等信息。垃圾收集器运行时,由于前面讲的不同步删除问题,这里会删除这些对象引用数为0的对象,这时会出现内存空洞(很多情况下,当我们的程序使用了未托管的资源时,如网络连接,数据库连接,文件连接,我们要手动释放这些资源所占的内存,通过使这些使用未托管资源的类实现IDispose接口是一个很好的做好)。下次在堆上为新对象分配内存时,肯定要进行扫描直至找到一块符合大小的内存块,这必然会增加实例化一个对象所花的时间,降低程序的性能。但垃圾收集器不可能让堆出现这种情况,它对在垃圾收集结束后重排内存,将留下的对象挪至到端(往低地址方向移),让堆指针指向堆的第一个空内存,下次实例化对象时从这里为对象分配空间即可,虽然这会花费一些时间,但是相比前面一种情况,微软相信性能能提高不少。同时,这也造成了一个问题,即指向类字段的指针的无效化,所以,一般情况下,c#不允许声明指向类字段的指针,就是这个堆对象的移动所造成的,但是通过fixed关键字,我们可以锁定对象,从而声明一个指向类字段的指针。如
unsafe { Program pro=new Program(); fixed(int* p_id=&(pro.id),p_age=&(pro.age)) fixed(double* p_salary=&(pro.salary)) { .....add code..... } } 上面申明了两个整型指针,一个双精度指针,它们分别指向类Program的几个字段。
高性能数组的构造。c#规定数组是引用类型,所以它分配在堆上,这和c++的不一样,c++的数组是值类型,它分配在栈上。栈的访问速度非常快,在要频繁访问某个数组的程序里,让这个数组分配在栈上,能提高程序的性能。通过stackalloc关键字,能实现这个功能,如下:
unsafe { double* p_nodes=stackalloc double[20]; int* p_ages=stackalloc int[20]; } 上面在栈上声明了两个大小为20的数组,通过*(p+k)或p[k]能访问数组的第k个元素。
好了,.net里面的指针功能其实很简单,主要在于我们何时使用,如我们读取一幅图片时,就可以只用指针功能,这能加快读取的速度。其他情况下还是慎用,因为可能造成整个程序的多处出现unsafe关键字,不好维护和管理,同时降低整个程序的安全性。




















