
编码:
最开始电脑的字符集是ASCII,英文在ASCII中每个字母占1个字节,但ASCII不支持中文,所以后来出现了Unicode;
Unicode中 英文和中文都占用两个字节,对于英文来说不合理,所以在Unicode的基础上出现了Unicode的扩展集UTF8;
UTF8中,英文如同ASCII一样,每个字母只占了1个字节,而每个中文占了3个字节;
目前中国Windows系统默认都是使用GBK字符集,如果一个软件使用的是GBK来开发的话,放到其他国家的电脑系统中,软件中的中文就会以乱码显示,因为其他国家电脑默认是不支持BGK的;
Unicode这个字符集所有国家电脑系统都支持,所以当想要把通过GBK开发的软件的中文,能在其他国家电脑中正常你显示就需要先将GBK转成Unicode,然后其他国家电脑系统可以用Unicode转成他们支持的字符集,反之亦然。
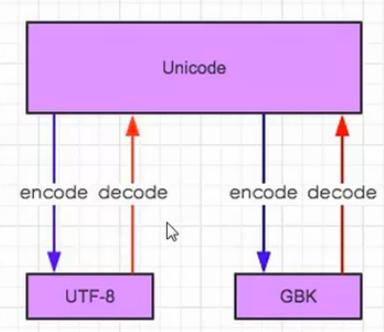 如图:一个编码想转成另一个编码,必须先decode成Unicode,然后在encode成其他编码。
如图:一个编码想转成另一个编码,必须先decode成Unicode,然后在encode成其他编码。
import sys
print (sys.getdefaultencoding()) #打印系统默认编码
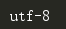 在python3中,默认是utf-8(utf-8属于unicode的扩展集)
在python3中,默认是utf-8(utf-8属于unicode的扩展集)
python2编码
import sys
print (sys.getdefaultencoding())
 在python2中,默认是ascii
在python2中,默认是ascii
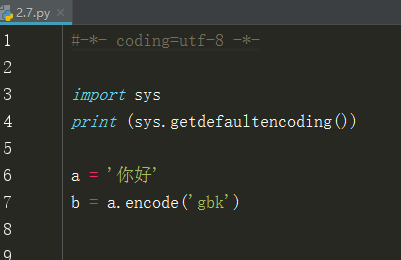
 在python2中,设置编码为utf-8;
写一个变量,这个变量会因为设置的原因,现在是utf-8
我们直接将这个变量(utf-8)进行转码到gbk,但是可以看到转码错误;正常转码之前,应该先解码成Unicode,但是我们这里没有做解码的操作,不过这里会自动做一个解码的操作,但这个自动解码的操作使用的是系统默认的ascii来解码,可我们的变量是utf-8,所以这里报错解码失败。
在python2中,设置编码为utf-8;
写一个变量,这个变量会因为设置的原因,现在是utf-8
我们直接将这个变量(utf-8)进行转码到gbk,但是可以看到转码错误;正常转码之前,应该先解码成Unicode,但是我们这里没有做解码的操作,不过这里会自动做一个解码的操作,但这个自动解码的操作使用的是系统默认的ascii来解码,可我们的变量是utf-8,所以这里报错解码失败。
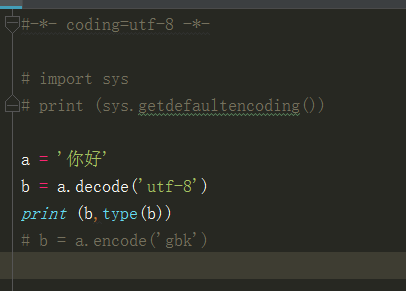 b = a.decode('utf-8') #这里指定源编码是utf-8,以utf-8为源编码转成unicode
b = a.decode('utf-8') #这里指定源编码是utf-8,以utf-8为源编码转成unicode
 这里我们先做一个解码操作,打印之后,我们可以看到打印type(b)可以正常显示是unicode,而打印的b却不正常,这是因为可以看到打印出来的是元组,unicode编码在元组中不会显示中文,只会以编码形的格式显示,在格式的前面有一个u,表示unicode;
这里我们先做一个解码操作,打印之后,我们可以看到打印type(b)可以正常显示是unicode,而打印的b却不正常,这是因为可以看到打印出来的是元组,unicode编码在元组中不会显示中文,只会以编码形的格式显示,在格式的前面有一个u,表示unicode;
print (b) #需要单独打印b,才不会以元组的形式打印

c = b.encode('gbk') #将unicode转成gbk
print (c)
 打印出来的是乱码,这是当前pycharm调整了编码模式为utf-8,所以打印gbk出来时是乱码
打印出来的是乱码,这是当前pycharm调整了编码模式为utf-8,所以打印gbk出来时是乱码
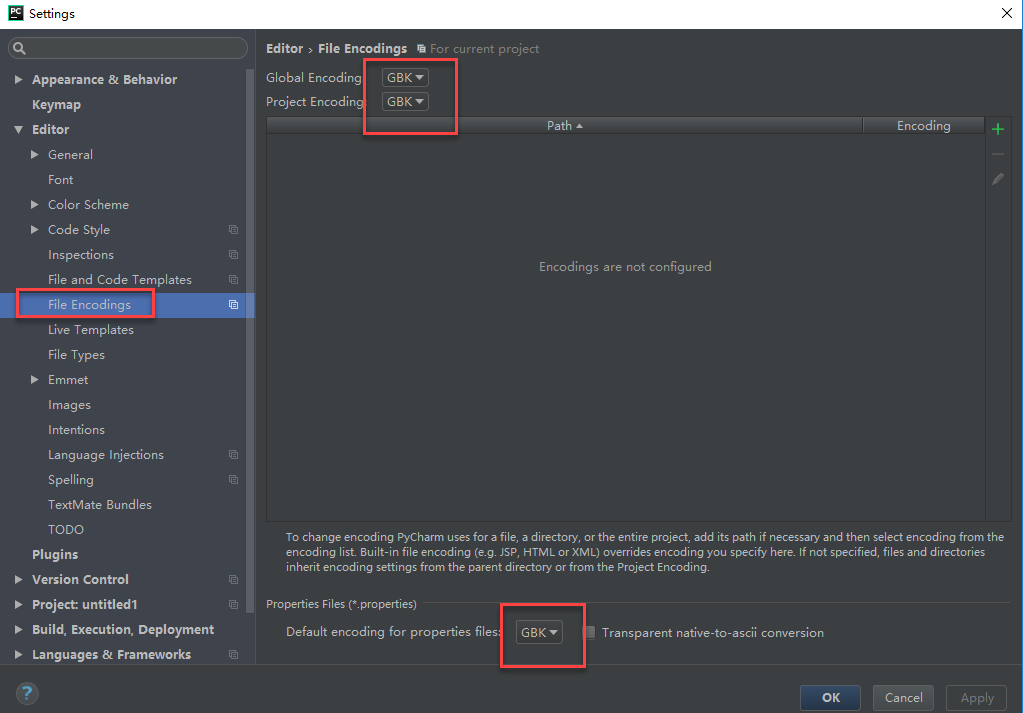 把pycharm改成GBK咋打印gbk就不是乱码了
把pycharm改成GBK咋打印gbk就不是乱码了

c = b.encode('gbk') #从unicode转成gbk
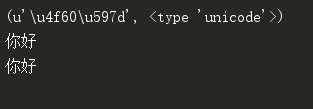 已经看到打印gbk不是乱码了,同时打印b(unicode)也同样不是乱码,这是因为unicode可以兼容所有编码,所以不会是乱码,如果这里是assic就会是乱码了
已经看到打印gbk不是乱码了,同时打印b(unicode)也同样不是乱码,这是因为unicode可以兼容所有编码,所以不会是乱码,如果这里是assic就会是乱码了
f = c.decode('gbk').encode('utf-8') #将当前的gbk解码为unicode,然后在编码为utf-8
print (f)
 打印出来是乱码
打印出来是乱码
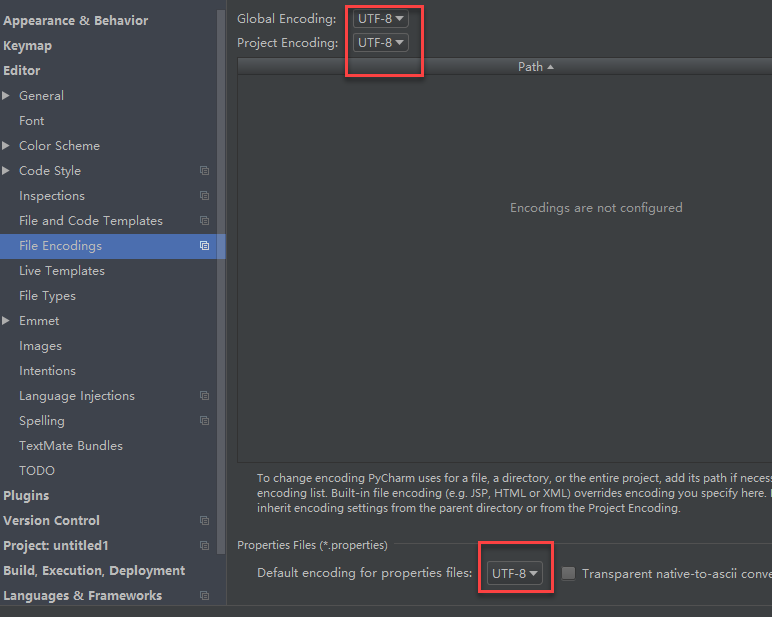
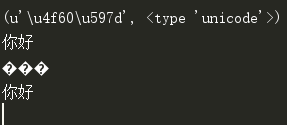 可以看到最后打印utf-8的已经不是乱码了; 不过在之上的gbk就成乱码了。
可以看到最后打印utf-8的已经不是乱码了; 不过在之上的gbk就成乱码了。
x = u'一二三' #在'一二三'前面有个u,表示直接转码为unicode
print (x)
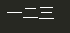 可以看到unicode在utf-8编码下也能正常显示。
y = x.encode('gbk') #unicode编码可以直接encode为其他编码
print (y)
可以看到unicode在utf-8编码下也能正常显示。
y = x.encode('gbk') #unicode编码可以直接encode为其他编码
print (y)
python3编码
import sys
print (sys.getdefaultencoding())
#python3默认就属于unicode,utf-8属于unicode的扩展集,所以也算是unicode
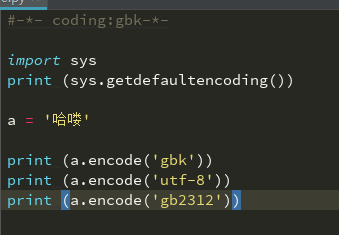
a = '哈喽'
print (a.encode('gbk')) #unicode可以直接转成其他编码
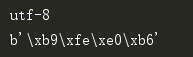 转成编码后因为当前pycharm是unicode,所以没有正常显示。
前面有个b,表示被转成bytes类型
转成编码后因为当前pycharm是unicode,所以没有正常显示。
前面有个b,表示被转成bytes类型
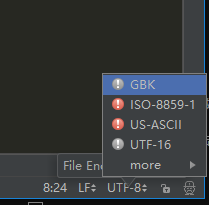 在pycharm的右下角可以直接转换编码为gbk,这里只是将文件编码转为gbk和程序的编码无关
在pycharm的右下角可以直接转换编码为gbk,这里只是将文件编码转为gbk和程序的编码无关
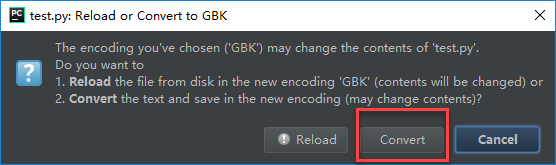 再去执行的时候,发现报错,这是因为之前写代码的时候默认是unicode,现在已经转换成gbk了,但是代码还是根据默认unicode来写的;
再去执行的时候,发现报错,这是因为之前写代码的时候默认是unicode,现在已经转换成gbk了,但是代码还是根据默认unicode来写的;
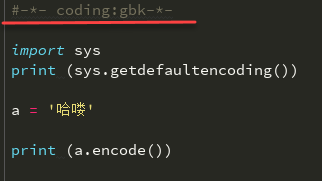 所以要在文件开头进行声明,文件编码是gbk,注意这里只是声明文件编码是gbk和程序编码无关;
目前python3程序默认还是unicode
所以要在文件开头进行声明,文件编码是gbk,注意这里只是声明文件编码是gbk和程序编码无关;
目前python3程序默认还是unicode
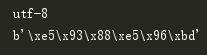 目前a = '哈喽'还是属于unicode(因为python3默认是unicode)
目前a = '哈喽'还是属于unicode(因为python3默认是unicode)
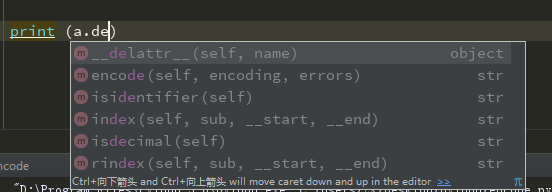 可以看到因为当前a属于unicode,所以不能做decode操作(图中没有decode可选)
可以看到因为当前a属于unicode,所以不能做decode操作(图中没有decode可选)
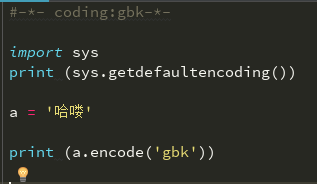 从unicode转成gbk
从unicode转成gbk
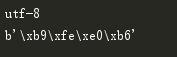 当前是bytes类型的数据,所以无法显示字符串
当前是bytes类型的数据,所以无法显示字符串
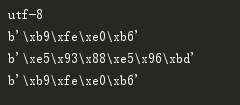 注意在python3中,encode后不光转了编码,还将数据编程bytes类型
注意在python3中,encode后不光转了编码,还将数据编程bytes类型
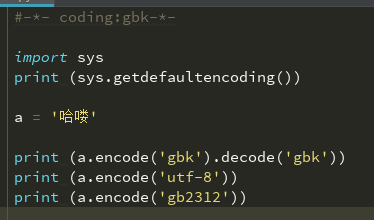
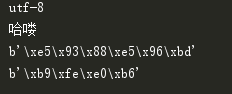 decode一下就可以显示中文字符串了。
decode一下就可以显示中文字符串了。
windows默认是gbk linux默认是utf-8 python2默认是ascii python3默认是unicode
最终要记住的就是,无论在python2还是在python3上,要做的是确认当前使用的编码集,任何非unicode编码集都要decode成unicode,然后通过unicode在encode成想要的编码集;
如果当前直接就是unicode,可以直接encode想要的编码集。
在python3上默认是unicode,中文和英文都按照两个字节存储,通过声明 -- coding:utf -8-- ,编码就为utf-8了,这样英文存储为1个字节,中文为3个字节。
chardet查看文件或字符串编码方式
import chardet
f = open('test.txt', 'rb')
data1 = f.read()
print(chardet.detect(data1))
print(chardet.detect(data1)['encoding'])
执行结果:
{'encoding': 'utf-8', 'confidence': 0.7525, 'language': ''} #字典格式
utf-8
isinstance判断编码是否为unicode
str_1 = 'ABC'
print('str_1 是否为 Unicode 编码:', isinstance(str_1, str))
执行结果:
str_1 是否为 Unicode 编码: True
str_2 = '中文'
if isinstance(str_2, str):
print('str2 为 Unicode编码。')
else:
print('str2 并非 Unicode编码。')
执行结果:
str2 为 Unicode编码。
str_3 = '中文'.encode('gbk')
if isinstance(str_3, str):
print('str3 为 Unicode编码。')
else:
print('str3 并非 Unicode编码。')
执行结果:
str3 并非 Unicode编码。



















