
缓存
在棋类比赛中,大师和一般棋手最大的区别在于精通许多定式,下棋时能够基于定式快速的进行判断 。定式的本质上是存储的预先计算好的中间结果,这样棋手在做判断时不需要重新计算而直接在大脑中调用存储的计算结果。在中学数学中做数学证明题时,需要用到合适的定理,定理和棋类的定式类似, 也是可以看作是存储的一系列关键的推理步骤的结果;这样在推理时就不需要从基本公理做起。
这两个例子是信息系统中缓存的两个特点,1)储存一系列计算/操作的结果 2)以备反复使用。 信息系统的缓存信息往往有一定的时效性,内容有可能过时。这是不同于定式/定理的地方。
大家常说缓存为王。缓存是提高系统效率最直接的办法。缓存直接和系统的效率优化相关,同时由于缓存节省了系统大量的计算资源,可以处理更多的请求, 全面利用缓存的系统构架也可以显著提高系统的可扩展性。
引入缓存也是有代价的。系统引入额外的缓存组件,增加了工作流程和系统自身的复杂度。而且缓存将特定信息复制在系统的不同部位,违反了软件设计里的DRY(DONT REPEAT YOURSELF)基本原则, 增加了出错诊断的难度。缓存系统停机的后果有可能很严重; 缓存可以看作服务器和用户端的缓冲区,设计运行良好的缓存可以消化大量的请求,当缓冲区不存在时,所有的请求都涌向服务器,往往造成服务器负载过高而停止工作, 最终影响整个网站的可用性。
在提高客户端的效率一节中, 我们提到了利用客户端缓存的几个模式:使用HTML报头的Expires; 缓存Ajax调用结果。 本节讨论服务器端的几个缓存模式。
(一)使用CDN(内容分发网络, Content Delivery Network)
CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。 (百度百科)
CDN的工作原理如下图
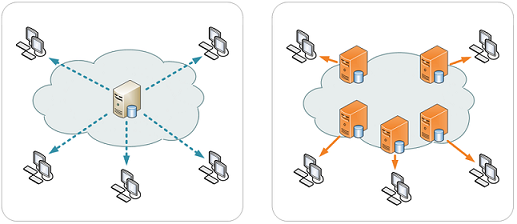
【摘自Wikipedia]
网络最初由点到点的设计原则构架。点A经过网络中的路由传输,最终将发送的请求交于点B,但是由于IP网络本身的“尽力而为的原则”、网络链路中复杂的环境及硬件的不可靠性的存在,导致发送到延迟。
CDN是通过骨架网(Backbone) 连接的一群边界服务器(Edge Server),用户内容(网页,图像等)被复制存储在多个服务器上。CDN使用几个关键技术优化内容发送。
-
Web缓存:自动生成服务器的远程镜像,用户访问时从缓存服务器(镜像)上读取数据,减少远程访问的带宽、分担网络流量、减轻原站点服务器负载等功能。 从而加速 提高了企业站点(尤其含有大量图片和静态页面站点)的访问速度,并大大提高站点的稳定性 。
-
服务器负载平衡
-
请求的路由控制: 通过内容路由器中的重定向(DNS)机制,将客户请求定向到最合适的边缘服务器。这可能是距离客户端请求最近的服务器节点,或者处理容量最大的服务器节点。
-
内容服务:借助于建立索引、缓存、流分裂、组播(Multicast)等技术,将内容发布或投递到距离用户最近的远程服务点(POP)处。
CDN不仅提高了内容的传输效率,由于其中结构上实现了多点的冗余,也提供了系统的可用性。而CDN分发解决方案解决了与静态网站相关的性能和可靠性问题;对于动态内容,Oracle, Vignette 和 FatWire等公司开发了标记语言ESI (Edge Side Includes)。 ESI用于在边界服务器上加速和缓存动态页面。ESI虽然还不是W3C的正式标准,Akamai等CDN供应商实现了ESI并在功能上有所扩展。
北美主要的CDN供应商以应用服务提供商形式营运。越来越多的网络运行公司(如AT&T 和 Level3)提供自己的CDN服务,来减少对自身的电信基础设施的依赖,提高信息分发效率。国内较为有名的CDN服务商有思必达 ,蓝汛等。
(二)使用 页面缓存(Page Caching)
对频繁访问但更改不太频繁的动态 Web 页使用页面缓存,Web 服务器维护包含预先生成的页面的本地数据存储 , 后续的客户请求 。页面缓存的基本结构如下:
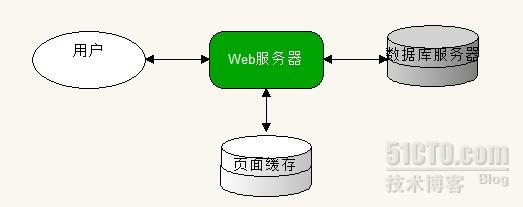
在缓存设计中,可以选存储量大而速度小的磁盘存储缓存,或者选择较小的但速度快内存缓存。缓存容量有限,在理想情况下,一般使用LFU(最不常使用)的策略 , 只缓存访问频率高的页面。对于静态页面, 存储完整页面 是最有效的办法; 但是如果页面的某些部分经常更新,可以对页面缓存进行优化,使用页面片段缓存(Page Fragment Caching), 在这种方式下,每一页都由片段组成,并在片段级别上控制缓存。 存储较小的片段虽然引入了更多的工作(比如从片段合成成完整页面),但是提高了片段的重复使用率.
页面缓存的优点包括节省生成页面需要的计算资源,节省客户端连接 ,支持许多页面请求的并发访问 。 页面缓存往往节省了对数据库或者其他外部数据源的访问,提供了系统可扩展性。 在外部数据源变得不可用时,页面缓存页也允许系统将已缓存页面传递给客户端, 提高应用程序的可用性。
页面缓存的一个替代方案是页面数据缓存(Page Data Caching),该方法缓存页面所依赖的数据而不是缓存整个页面。
(三)使用缓存降低系统之间的偶联
时间顺序上的限制往往造成了系统之间的高度的依赖性。以网上订票网站为例,订票需要关于机票价格,所余票数的即时信息;这类信息是第3方不同的航空公司提供的,这类调用不仅是收费的, 而且对第三方系统的调用,影响了自身的性能和可用性。
如果在机票信息的即时性上做出妥协,将调用的结果缓存,同时保证缓存的更新(比如每1分钟),这样不仅降低了成本,提高了调用效率,而且也消除了第三方系统的不确定性(比如延时,不工作)对系统稳定性的直接影响。 虽然放松了即时性可能造成少量的出票错误, 实践证明系统反应加速带来的用户体验,商业价值远远超过了对少量客户的影响。
(四)应用80/20法则更有效的使用缓存。
帕累托法则(Pareto Principle)也就是著名的80/20法则,揭示了经济学中的一个普遍现象;. 投入和努力可以分为两种不同的类型: 80%的产出源自20%的投入. 产品或服务的20%创造了80%的利润 ,大多数软件用80%的时间仅仅完成20%的有效指令.
缓存系统尤其是使用内存的高速缓存系统的容量有限,往往通过LRU(最近最少使用置换算法 Least Recently Used ),置换出不常用的数据。如何去帮助产生主要价值的少数数据不被大多数的低价值数据置换呢?
如果20%的用户产生80%的交易数据,可以先把20%映射到所有数据库缓存分区,余下的80%用户再平均分配到这些分区(Abbott和Fisher);如果 80%商业价值是由20%的请求的数据实现的, 如果这些请求的模式可以确定(比如来自那些用户),一种方式是希望把这些的用户(往往也是最有商业价值)映射专门的高性能的缓存分区上。
(四)使用对象缓存
对象缓存是将消耗计算资源(复杂的数据库搜索,或其他操作)获得的结果整体缓存的一种策略。常见的对象缓存系统包括Memcached, Apaches OJB等。
这是Memcache官网上使用memcache的一个例子。
|
//先查询Memcache缓存,是否含有数据 $huge_data_for_front_page = $memcache->get("huge_data_for_front_page"); //要么是缓存中数据失效,要么是没存过,没办法,只好从数据库中重新查询 if($huge_data_for_front_page === false){ $huge_data_for_front_page = array(); $sql = "SELECT * FROM hugetable WHERE timestamp > lastweek ORDER BY timestamp ASC LIMIT 50000"; $res = mysql_query($sql, $mysql_connection); while($rec = mysql_fetch_assoc($res)){ $huge_data_for_frong_page[] = $rec; } //把查询的整个结果数组放入memcache缓存, 因此称为“对象缓存” // 缓存保存 10 分钟 $memcache->set("huge_data_for_front_page", $huge_data_for_front_page, 0, 600); }
|
系统中数据库查询往往占用计算资源最多,是系统扩展性的瓶颈。因此需要对数据库使用对象缓存。 一般数据库管理系统都有分析软件提供各个SQL查询的执行计划,CPU和内存使用,情况,最耗时和最常用的查询等,这些都是决定哪些查询结果需要缓存的参考因素。用于缓存查询的关键字是 产生缓存对象的原始查询数据的哈希值(校验值)。
Hibernate,iBatics 等ORM平台往往都提供对象缓存的直接支持。以Hibernate为例,Hibernate的缓存分两级。一级缓存是Session缓存,保存Session对象数据, 是属于事务范围的缓存,二级缓存由SessionFactory创建的所有Session对象共享使用,属于进程范围和群集范围的缓存。 二级缓存可使用EHCache、 OSChahe JBossCache等第三方的缓存插件。二级缓存包括类缓存、集合缓存和查询缓存(Query Cache)。
Hibernate实现查询缓存的步骤大致如下:
1. 根据条件查询请求的信息(SQL 和参数)形成一个Query Key.
-
根据Query Key 到查询缓存中查找对应的结果列表,如果发现,返回该结果列表,否则查询数据库,获取结果列表,把(Qury Key,结果列表)放入查询缓存。
-
Query Key中的SQL涉及到一些表名。如果这些表发生任何的数据修改,QueryKey都要从缓存中清除。
模式名称 使用CDN
描述: 使用CDN优化内容发布效率,降低服务器负载
动机/试图解决问题: Web传统的点到点的传播模式受网络不可靠性的影响,导致发送到延迟。
原理: CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。加上CDN提供的缓存,冗余模式, 提高了网站的效率和可用性。
使用: 一定规模的网站公司。
模式名称 使用页面缓存
描述: 对频繁访问但更改不太频繁的动态 Web 页使用页面缓存。
动机/试图解决问题: 过高的并发请求影响Web服务器的性能
原理: Web 服务器维护包含预先生成的页面的本地数据存储 , 后续的客户请求直接返回缓存的结果,减少了Web服务器的负载,提高了反应速度 。
使用: 设置在Web服务的前端。
模式名称 使用缓存降低系统之间的偶联
描述: 使用缓存降低系统之间的时间相关性的偶联
动机/试图解决问题: 当系统之间存在直接的因果时间顺序,将影响系统整体的稳定性和可扩展性。
原理: 直接调用的系统之间加入缓存区, 放宽系统之间调用的即时因果顺序限制。 降低了系统间的紧密偶联, 提高了调用的效率,和系统整体的稳定性和可扩展性。
使用:
模式名称 应用80/20法则更有效的使用缓存。
描述: 应用80/20法则区分重要数据和一般数据, 对重要数据提供更好的缓存服务。
动机/试图解决问题: 缓存有大小上限。 数据的商业价值也不尽相同。需要对重要数据提供更好的缓存服务。
原理: 基于实际的80/20 的数据对象的分布,决定缓存的设置。
使用:
模式名称 使用对象缓存
描述: 对于消耗大量计算资源的计算结果, 缓存以备重用。
动机/试图解决问题: 数据库查询需要大量计算资源,往往是系统可扩展性的瓶颈。
原理: 将整个查询结果缓存, 提高效率。
使用:
总结:
在系统的各个层次充分使用缓存技术,可以在提高系统的效率的同时提高其可扩展性。



















