
从 SQL 到集算器的基本查询语法迁移(一)单表操作

数据库和数据分析领域,有一个强大的存在,大名 SQL,全名结构化查询语言 (Structured Query Language)。从字面上看,这个语言的目标就是把数据“查询”出来,而查询这个词给人的感觉并不是很难。但实际上,为了支持貌似简单的查询,需要进行大量的计算动作,甚至整个过程就是一个多步骤的计算,前后步骤之间还有很强的依赖关系,前面计算的结果要被后面使用,而后面的输出有可能需要我们对前面的计算进行调整。
打个比方,这有点类似于去各类网点办事,填表递交后,相关办事人员开始在窗口后忙忙碌碌,时不时还会甩回来几个问题要求澄清,等到最后拿到回复,还有可能根本不是自己期望的结果!这时候,坐在办事窗口外的我们,抓狂之余,往往会产生一个念头,如果我们能够看到,甚至参与到过程中,应该能够大大地提高办事效率。
没错,你应该能想到,下面要介绍的集算器,和 SQL 相比对于我们这些过程控来说,就是一个可以轻松把玩和控制的计算(不止是查询)工具。
我们要做的,就是“照猫画虎”地把习惯中的 SQL 操作迁移到集算器中,用小小的习惯改变,换来大大的效益提升。
首先,我们需要把数据从传统的数据源中“搬迁”到集算器中,这样后续的操作就可以完全在集算器中进行了。
我们最常用的数据源一般就是关系数据库 RDB。这里使用的样例数据,就是数据库中的两个数据表:
订单信息表(order,主键 orderId),包括订单编号orderId、客户代码customerId、雇员编号employeeId、订单日期orderDate、发送日期sendDate以及金额money****:
| orderId | customerId | employeeId | orderDate | sendDate | money |
|---|---|---|---|---|---|
| 10248 | VINET | 2 | 2011-02-04 | 2011-02-16 | 440 |
| 10249 | TOMSP | 9 | 2011-02-05 | 2011-02-10 | 1863 |
| 10250 | HANAR | 9 | 2011-02-08 | 2011-02-12 | 1813 |
| 10251 | VICTE | 9 | 2011-02-08 | 2011-02-15 | 670 |
订单明细表(orderDetail,主键 orderId,productId),包括订单编号orderId、产品编号productId、价格price、数量amount、折扣discount:
| orderId | productId | price | amount | discount |
|---|---|---|---|---|
| 11059 | 17 | 39 | 12 | 0.85 |
| 11059 | 60 | 34 | 35 | 0.9 |
| 11060 | 60 | 34 | 4 | 1 |
| 11060 | 77 | 13 | 10 | 0.95 |
“搬迁”,或者说导入数据的过程非常简单,如下图所示:
| 集算器 | A |
|---|---|
| 1 | =connect(“hsqlDB”) |
| 2 | =A1.query(“select * from order”) |
| 3 | >A1.close() |
首先建立数据库连接(网格 A1),然后直接通过单表全量查询的 SQL 语句从数据库中读取数据(网格 A2),最后清理现场,关闭数据库连接(网格 A3)。
在执行了脚本后,我们可以选中网格 A2,在结果区中看看搬过来的数据,同时,order 表在集算器中也换了个身份,我们称之为“序表”,用网格名称 A2 代表。序表是集算器中一个非常重要的概念,现在我们可以简单地把它理解成对应数据库中的一张表:
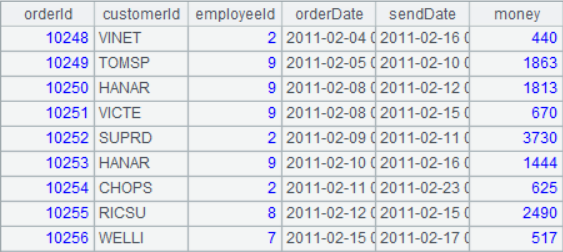
其实,在集算器中,任何一个有计算结果的网格(一般是用等号“=”开始),都可以在执行脚本后,随时选中并查看结果,并通过网格名称 A7、B8 等随时引用,从而满足我们随时监控的欲望……
接下来,我们以 SQL 中 select 语句的各个子句为线索,看看集算器中是如何操作的:
第一个:SELECT 子句
用来选择需要查询的字段,也可以通过表达式来对字段进行计算,或者重命名字段。与之对应的,集算器里有 new、derive、run 三个函数。
例如:只选出订单表里的订单编号、雇员编号、订单日期以及金额字段,同时把金额乘以 100 后使它的单位从元变成分,把相应的结果字段重命名为 centMoney。
SQL 的做法如下:
| SQL |
|---|
| SELECT orderId,employeeId,orderDate,money*100 centMoney FROM order |
集算器对应的做法是下表中的 A3:
| 集算器 | A |
|---|---|
| 1 | =connect(“hsqlDB”) |
| 2 | =A1.query(“SELECT * FROM order”) |
| 3 | =A2.new(orderId,employeeId,orderDate,money*100:centMoney) |
| 4 | =A3.derive(year(orderDate):orderYear) |
| 5 | =A4.run(string(orderYear)+”年”:orderYear) |
| 6 | >A1.close() |
A3 利用 A2 的数据新建了一个序表,包含了要求的字段,包括把金额乘以 100 后用 centMoney 命名:
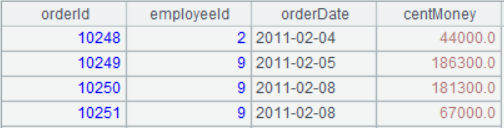
我们继续看下 A4 的结果,在序表 A3 的原有字段后增加了新字段 orderYear,这也就是说 derive(新计算字段) 相当于 new(所有老字段, 新计算字段),可以看做是 new 函数的一种简单的写法,免去了把老字段再抄写一遍。

A5 使用了 run 函数,直接作用是修改老字段 orderYear 的值,但是再看 A4 的结果,也变成和 A5 一样了。这是因为 run 函数并没有像 new、derive 函数那样生成新的序表对象,而是在原来对象上直接做修改。
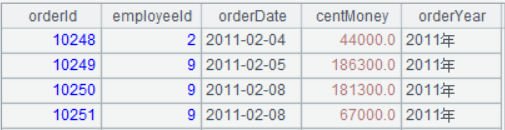
总结一下,在集算器中,new、derive、run 函数都会产生序表结果,但是 new、derive 函数会生成一个新的序表对象,像是把数据复制出来(这个行为有个专有名词immutable),而 run 则直接修改被处理对象(行为属于mutable)。
【延伸阅读】之所以提出mutable这样的行为,有两个因素:首先是减少内存占用,从而提高性能;其次,有些实际业务的需求就需要改变原有对象,一系列的动作直接作用在一个对象上,到最后一步就得到正确结果了,而不是得到一堆中间结果,再做最后合并的动作。当然 immutable 也有它的适用场景,两种行为本身没有优劣之分。
第二个:WHERE 子句
用来对数据表按条件进行过滤。与之对应的,集算器通过 select 函数对一个序表的记录进行过滤。效果如下图所示:
针对前面的示例数据,我们希望查询指定时段(2012 年 1 月期间)的订单数据,可以对比一下 SQL 和集算器(网格 A3)的做法。
| SQL |
|---|
| SELECT * FROM order |
| WHERE orderDate>=’2012-01-01′ AND orderDate<‘2012-02-01’ |
| 集算器 | A |
|---|---|
| 1 | =connect(“hsqlDB”) |
| 2 | =A1.query(“SELECT * FROM order”) |
| 3 | =A2.select(orderDate>=date(“2012-01-01”) && orderDate<date(“2012-02-01”)) |
| 4 | >A1.close() |
需要注意一下集算器表达式中有两个细节:一是用了 date 函数把字符串转换成日期类型,二是 AND/OR 在集算器里的写法是 &&/||。
A3 的结果如下:
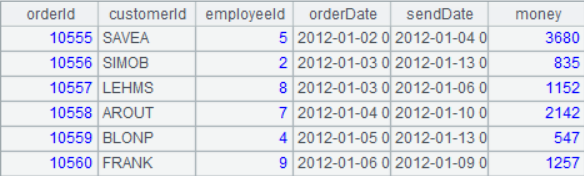
看起来和 A2 结构一致,只是数据量小了。但是我们可以做一个实验,在网格 B3 中输入“=A2.select(orderId=10555).run(money*10:money)”,修改 A2 序表中某些记录的字段值,可以看到 A3 序表里这些对应记录的值也跟着变化了。这就说明两个序表里的记录就是同一个东西(叫做对象会显得更专业点),也就是说集算器里的 select 函数属于我们前面所说的 mutable 行为。
第三个:GROUP BY 子句
GROUPY BY 经常和聚合函数 SUM、COUNT 等一起出现,用来将查询结果按照某些字段进行归类分组,并汇总统计。严格来说,这是两个独立的动作,但在 SQL 中总是一起出现,从而给人一种两者必须同时使用的假象。事实上,这种组合是对分组操作的一种局限,或者说分组之后,能够进行的计算远不止 SQL 中的几种聚合函数。在集算器中,与 GROUP BY 子句对应的是 group 函数,它可以只对数据纯粹分组,每组形成一个小集合,在后面的计算中可以针对这些小集合进行简单的聚合,也可以进行更加复杂的计算。下图是 SQL 中利用 GROUP BY 进行分组求和的示意:
同样还是前面的示例数据,我们希望计算 2012 年 1 月期间每个雇员的销售总额,也就是按照雇员编号分组后求和。针对这个分组求和的计算,我们对比一下 SQL 和集算器的做法:
| SQL |
|---|
| SELECT employeeId, sum(money) salesAmount FROM order WHERE orderDate>=’2012-01-01′ AND orderDate<‘2012-02-01’ GROUP BY employeeId |
| 集算器 | A |
|---|---|
| 1 | =connect(“hsqlDB”) |
| 2 | =A1.query(“SELECT * FROM order”) |
| 3 | =A2.select(orderDate>=date(“2012-01-01”) && orderDate<date(“2012-02-01”)) |
| 4 | =A3.group(employeeId;~.sum(money):salesAmount) |
| 5 | >A1.close() |
A4 的结果如下:

集算器把查询分解成了三步:
首先,是 A2 取出订单表中的所有记录;
然后,A3 过滤得到指定时段(2012 年 1 月期间)的订单记录
最后,A4 把过滤得到的记录按照雇员编号进行分组(由函数参数中分号前的部分定义,可以同时指定多个字段),同时对每个分组(用“~”符号表示)进行求和(sum)计算,并把计算结果的字段命名为 salesAmount(分号后的部分)
看起来和 SQL 分组没什么不用,这只是因为我们这个例子只演示了和 SQL 相同的分组查询。实际上 A4 里 group 函数的后半部分不是必须的,也可能有的业务仅仅是想得到分组后的结果,而不在这里进行求和、计数运算;也可能针对特定值的分组有不同的聚合运算,那就针对分组后的小集合“~”写更复杂的表达式就可以了。
同时,在其他教程中,我们还可以了解到,分组字段不局限于原始字段,可以是一个表达式,这个和 SQL 里一样。
单纯的分组属于mutable行为,是把一个大集合的记录拆分到多个小集合里。而加上聚合运算后,因为产生了新的数据结构,就不再是简单的把原有记录挪挪地方的操作了。
第四个:HAVING 子句
用来对 GROUP BY 后的聚合结果再进行过滤。在集算器里,就没有专门对应 HAVING 的函数了,对任何序表按照条件过滤都用 select 函数,因为计算是分步的,操作指向的对象总是明确的。而 SQL 要求一句话把所有事情表达出来,遇到复杂查询,就难免出现对同一性质的操作增加概念,以表达作用到不同的对象上。再深想一下,HAVING 概念在 SQL 里也不是必须的,它是对第一层子查询的简化写法:
SELECT f1, sum(f2) f2 FROM t GROUP BY f1 HAVING sum(f2)>100
等价于
SELECT * FROM
(SELECT f1, sum(f2) f2sum FROM t GROUP BY f1) t2
WHERE f2sum >100
对更多层子查询做同类简化,估计会出现 HAVING2、HAVING3…类似的关键字,但 HAVING2 之后的简化性价比不高,SQL 也就没有提供了。这里又体现出分步计算的一个优势,只需要描述计算本质需要的概念,HAVING、子查询这些因为技术手段被迫产生的概念就可以弃用了。减少非必要概念是降低学习成本的重要手段。
我们具体看一下 SQL 和集算器的做法的对比,找到 2012 年 1 月期间销售额超过 5000 的雇员编号和他的销售总额:
| SQL |
|---|
| SELECT employeeId, SUM(money) salesAmount FROM order WHERE orderDate>=’2012-01-01′ AND orderDate<‘2012-02-01’ GROUP BY employeeId HAVING SUM(money)>5000 |
| 集算器 | A |
|---|---|
| 1 | =connect(“hsqlDB”) |
| 2 | =A1.query(“SELECT * FROM order”) |
| 3 | =A2.select(orderDate>=date(“2012-01-01”) && orderDate<date(“2012-02-01”)) |
| 4 | =A3.group(employeeId;~.sum(money):salesAmount) |
| 5 | =A4.select(salesAmount>5000) |
| 6 | >A1.close() |
A5 结果
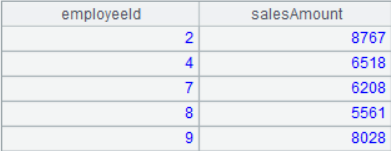
随着查询复杂度逐步提升,集算器语句容易阅读,步骤流程清晰的特点也就凸显出来了。每一步都可以观察结果,根据结果随意控制计算流程,用最精简的概念描述每个计算步骤。这还只是一个最简单的单表查询例子,下一篇我们会继续了解在多表连接和联合的情况下,集算器会有怎样更加优秀的表现。


















