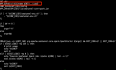
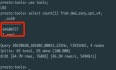
报错内容如下:2022-09-29T10:19:39,785 ERROR [be6bd8ac-4a04-4f23-ac2a-540949dea68a main] metadata.HiveMetaStoreChecker: org.apache.hadoop.hive.ql.metadata.HiveException: Unexpected partition key hour found at
公司的数据变更字段时出现以下报错:java.net.SocketTimeoutException: Read timed out原因:hive.metastore.client.socket.timeout的值,目前是300。 解决方案:hive.metastore.client.socket.timeout的值,改为1000。
公司用的是原生的Hadoop,执行hadoop fs -ls /的时候出现以下hadoop的配置打印出来 原因是因为hadoop的文件中别人在前面加了set -x解决方案:vim /opt/hadoop/bin/hadoop把set -x改为set +x问题解决
Presto查询的时候报错User: wangyx@XXX.COM is not allowed to impersonate wangyx2022-09-19T14:37:42.936+0800 DEBUG query-execution-1 com.facebook.presto.execution.QueryStateMachine Query 20220919_0637
hive3.1.2用的cdh6.3.2中自带的spark2.4,在beeline客户端中,切换执行引擎为spark报错,报错为加载配置文件报加载不到解决方案检查了hive-site.xml文件,缺了一个配置,就是spark.yarn.jars
提示check failure stack trace解决方案:主要的原因是因为配置的问题,更改为正确的配置后,问题解决
安装presto的时候,报jdk版本不兼容的问题解决方案,提示最低需要java 8u151及以上版本vim /data/presto/bin/launcher export JAVA_HOME=/opt/jdk1.8.0_151export PATH=$JAVA_HOME/bin:$PATHjava -versionexec "$(dirname "$0")/launcher.py" "$@" #
解决方案排查了一下krb5.conf文件,发现我之前的配置少了一行配置udp_preference_limit = 1这个配置,加上之后问题解决
一、登录mysql操作use hive;(1)修改表字段注解和表注解alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;(2)修改
flink在提交任务到yarn上的时候,提示yarnCluster的问题,查看yarn上的资源是够的解决方案:查看了yarn的主从节点进行了切换导致无法分配资源,重启rm节点,把rm节点还原到原来的状态后,问解决。
原生的启用nodemanager报错如下cat /var/log/hadoop/hadoop-root-nodemanager-cd-cp-standby20.wxxdc.log 2022-08-18 15:12:57,355 INFO org.apache.hadoop.yarn.server.nodemanager.NodeManager: STARTUP_MSG: /************
SparkStreamingFlink定义弹性分布式数据集,并非真正的实时计算真正的实时计算,就像storm一样,但flink同时支持有限的数据流计算(批处理)高容错基于RDD和checkpoint比较沉重checkpoint(快照),比较轻量级内存管理JVM相关操作显露给用户Flink在JVM中实现的是自己的内存管理延时中等100ms低10ms
1代:Hadoop MapReduce批处理Mapper、Reducer2代:DAG框架(Oozie、Tez) Tez+MapReduce批处理1个 Tez = MR(2) +....+MR(n)相比MR效率有所提升。3代:Spark批处理、流处理、SQL高层API支持 自带DAG 内存迭代计算、性能较之前大幅提升4代:Flink批处理、流处理、SQL高层API支持 自带DAG 流式计算性能更高、
架构设计1.1系统架构图1.2启动流程图1.3架构说明MasterServerMasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处
企业: 第一个方面: 数据分析 第二个方面: 数据检索基本组件: * Zookeeper 分布式协作框架 节点数目 测试集群:3 个 生产集群: >> 小型集群, 3 个或者 5个 >> 中型机群,5 个 或者 7个 >> 大型机群, 奇数个 * HDFS 存储海量数据 * YARN 集群资源管理 资源调度 * MapReduce 并行计算框架 思想: 分而治之
进入服务器,查询正在执行任务的语句SELECT query_id,user, query FROM system.processes;-- 通过上面指令获取到进程相关信息后,可以用query_id条件kill进程KILL QUERY WHERE query_id='67cadc87-34b2-4b81-8f8c-087485c922af' -- 杀死default用户下的所有进程KILL QUE
问题现象:就是beeline客户端连接hive的时候更换引擎为tez执行报错,用mr就不报错,同样的语句在hive cli中,更换引擎为tez不报错,mr引擎执行也不报错解决方案:之前这个配置为false就报错改成true
问题描述:yarn开启ACL用户认证之后,日志只有在任务执行的时候能看到,SPARK任务跑完之后,在去看日志报User[yarn] is not authorized to view the logs for container的提示解决方案:主要是原因是我开启sentry认证之后,资源池的队列用ACL进行了管理,提交的时候都是以hive用户来提交的,在ACL中只加了root忘记加hive和yar
[INFO] 2022-07-06 13:12:16.714 - [taskAppId=TASK-393-81727-908774]:[238] - process has exited, execute path:/data/dolphinscheduler/exec/process/9/393/81727/908774, processId:25215 ,exitStatusCode:1 ,
提示是root账号没有权限读取这个路径解决方案:所有的hive的服务器上执行以下操作usermod -a -G hive root #把root账号加入到Hive组中重新查询:果然不在报错,问题解决。
在Yarn启动Flink主要的两种方式:1.启动一个Yarn Session:在Yarn内部初始化一个Flink集群常驻一直运行。2.直接在Yarn上提交运行Flink作业:每次提交一个Job到Yarn集群,Yarn集群开辟资源初始化一个Flink集群
Cloudera Manager1.1 cloudera manager的概念简单来说,Cloudera Manager是一个拥有集群自动化安装、中心化管理、集群监控、报警功能的一个工具(软件),使得安装集群从几天的时间缩短在几个小时内,运维人员从数十人降低到几人以内,极大的提高集群管理的效率。1.2 cloudera manager的功能管理:对集群进行管理,如添加、删除节点等操作。监控:
字面理解为文件操作超租期,实际上就是data stream操作过程中文件被删掉了。以前也遇到过,通常是因为Mapred多个task操作同一个文件,一个task完成后删掉文件导致。修改1、datanode所在的linux服务器提高文件句柄参数;2、增加HDFS的datanode句柄参数:dfs.datanode.max.transfer.threads。修改hdfs-site.xml&
22/06/26 19:03:45 INFO client.SparkClientImpl: 22/06/26 19:03:45 INFO conf.Configuration: resource-types.xml not found22/06/26 19:03:45 INFO client.SparkClientImpl: 22/06/26 19:03:45 INFO resource.Res
最低Java版本从7升级到8引入纠删码(Erasure Coding)主要解决数据量大到一定程度磁盘空间存储能力不足的问题.HDFS中的默认3副本方案在存储空间中具有200%的额外开销。但是,对于I/O活动相对较少冷数据集,在正常操作期间很少访问其他块副本,但仍然会消耗与第一个副本相同的资源量。纠删码能勾在不到50%数据冗余的情况下提供和3副本相同的容错能力,因此,使用纠删码作为副本机制的改进是自
1.在gw05机器上运行 nc -l 99992.切换到flink用户 sudo su - flink3.提交jar包flink run -m yarn-cluster -d -yjm 1024 -ytm 1024 -ys 2 -c com.dangbei.flink_test.wordcount.Test_WordCount -yD taskmanager.memory.managed.fra
hdfs fsck /tmp/logs/tools/logs/ -files -blocks -locations -racks
原理说明Elasticsearch 是一个实时的分布式的可扩展的使用REST接口的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。它基于Apache Lucene (TM)的开源搜索引擎,Lucene 非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。Elasticsearch 也是使用 Java 编写并使用 Lucene 来建立索引
Copyright © 2005-2025 51CTO.COM 版权所有 京ICP证060544号