经过近期线上环境打磨和验证,重新优化了grpc专题中的框架,优化和扩展了很多功能。如果读者之前未关注过,建议先了解此系列中的:快速开始 和 开始准备 这两小章。专题系列: 从零开始搭建grpc分布式应用完整源码:github源码一、概述base-grpc-framework是笔者自行开发和封装的一个server
基于本框架中的封装实现的分页逻辑,用一个例子来说明,为了简单整体结构分为三层(controller、service、dao),省略掉了grpc。以下注释中有******的是和业务相关的写法,需自定义。一、Controller@Slf4j@RestController@RequestMapping("/datadbase")public class DatabaseController { @
实话来讲,真不赞成用python写业务服务端代码。本章是用python语言实现的一套grpc框架,例子不太复杂,实现了就是基于grpc从零开始搭建一个准生产分布式应用(系列) 这里的例子。笔者在实现demo时踩了好多坑,因为网上资料很少。程序下载地址:demo-python源码 提取码: 26kv一、安装必要的库下表中的包的版本有些一定要一样,不然会出现应用不了protobuf的问
本章主要说一点高级的编程技巧,也是python中最常用的一种技巧--元类。有点类似于拦截器或AOP的功能。一、控制类的创建对象的类型叫作类,类的类型叫作元类。实例对象由类创建,而类则是由元类创建。类进行创建时会优先执行以下几个方法,通过复写这几个方法就可以控制类的创建过程,规范化代码,然后在类定义时使用metaclass来定义行为,以下三个方法会按顺序执行;__prepare__(定义类)__ne
本章会原生的库实现简单的Http调用,需要用到requests、urllib和http.client库。
python 死锁
一、文件读写文件读取需要注意三个问题:1、with上下文环境;2、换行符;3、编码(编码可用sys.gefdefaultencoding()取得系统默认编码)。如果想绕过文件编码层可直接访问buffer属性如 sys.stduout.buffer.write();1.1、读写文本文件open中有几种模式【文件格式+打开方式】,文件格式:文本-t,二进制-b,压缩文件-t。打开方式:r-读,w-写。
一、模块1.1、__init__.py在每个文件夹下创建__init__.py文件,这个文件将在此包下具体的模块导入之前执行。它里面可以定义与模块相关的一些内容。比如发布:下面代码只导入spam 和 grok。如果采用from module import *则会导入所有不以下划线开头的模块。但若定义了__all__则只有被列举出的模块才会被导入,如果定义了一个空列表,则不会导入任何模块。def s
本章算是为下面的类的内容打了点提前量。一、基础1.1、toString方法class FormatChange: def __init__(self, x, y): self.x = x self.y = y def __repr__(self): return f'use repr method: ({self.x}, {self.y})'
时至今日,Python的应用场景应用的越来越广泛,比如运维、AI学习等。可以认为是一项必要掌握的技能了。笔者会新开一个系列课程,真真正正的从0开始熟悉这门语言。整个系列会涉及3大块内容:1、Python基础;2、用ptyhon实现笔者的另一个系列(grpc分布式框架)中的服务程序;3、AI机器学习的内容。笔者的开发环境:macos、pycharm、anaconda, python版本:python
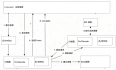
微服务本质上是一种设计模式,一种指导思想。在落地实现时有多种技术选型。在一些文献中也会对其概念、思想、以及与SP或单体服务做些一些对比。这些内容在笔者看来只能是靠个人的理解和悟性来归纳总结,所以就不在此进行描述了。本文会贴合技术来描述下微服务的一些基础知识点。一、基础完整的架构如下图所示:1.1、服务注册发现 服务注册就是维护一个登记簿,它管理系统内所有的服务地址。当新的
一、栈(stack)栈(stack)是限制插入和删除只能在一个位置上进行的表,该位置是表的末端,叫做栈顶 (top)。它是后进先出(LIFO)的。对栈的基本操作只有 push(进栈)和 pop(出栈)两种, 前者相当于插入,后者相当于删除最后的元素。 二、队列(queue) 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(re
一、原理Netty 是一个高性能、异步事件驱动的 NIO 框架,基于 JAVA NIO 提供的 API 实现。它提供了对 TCP、UDP 和文件传输的支持,作为一个异步 NIO 框架,Netty 的所有 IO 操作都是异步非阻塞 的,通过 Future-Listener 机制,用户可以方便的主动获取或者通过通知机制获得 IO 操作结果。 二、核心设计在 IO 编程过程中,
本章简单聊下网络和LBS相关的内容,本文中描述的都是基础部分。一般的公司会在基础上封装成需要的基础服务。网络分4层和7层:4层:网络访问层、网络层、传输层、应用层;7层:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层;一、网络1.1、TCP/IP原理TCP/IP 协议不是 TCP 和 IP 这两个协议的合称,而是指因特网整个 TCP/IP 协议族。从协议分层 模型方面来讲,TCP/IP
一、概念 RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。 AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言 等条件的限制。 RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用
一、概念Kafka 是一种高吞吐量、分布式、基于发布/订阅的消息系统,最初由 LinkedIn 公司开发,使用 Scala 语言编写,目前是 Apache 的开源项目。broker:Kafka 服务器,负责消息存储和转发;topic:消息类别,Kafka 按照 topic 来分类消息;partition:topic 的分区,一个 topic 可以包含多个 partition,topic 消息保存在
开始前必读:基于grpc从零开始搭建一个准生产分布式应用(0) - quickStart 前面章节的GRPC内基本是一个空实现,本章就实现下service业务逻辑层代码,因例子比较简单代码量也不算大,本章代码任务:1、用spring实现服务层,熟悉各注解的使用;2、实现一个VO逻辑,巩固mapStruct框架的使用。一、工程结构本章只涉及【base-grpc-framework-
本章开始会进入GRPC子专题,先实现前面章节中提到的例子。然后就使用的知识点展开全面的描述。本章代码任务:1、实现一个简单的GRPC服务;2、实现GRPC拦截器。 本章的代码承接上一章的代码进行迭代。因模块间存在相互依赖关系,读者一定先按笔者讲述的顺序操作,否则最后程序可能由于依赖问题导致不能运行;
工程的构建工作一般很容易被忽略,通常认为只是创建几个目录存储代码用而已。其实不然,工程目录结构合理与否除了直接会影响工程打包和上线流程,还会影响开发效率以及重构。工程目录设计除了符合系统架构外,还要符合小组成员的开发习惯。所以在开发新项目或是优化祖传代码时一定要把这件事做为一件非常重要的事来对待,否则过程中重构工程结构的代价会非常大,想想N多代码需要迁移、多个分支在开发、还要大量的回归测试等等。
本来笔者并不想开设这个系列,因为工作量比较大,另外此专题的技术点也偏简单。最近复盘了下最近的工作,发现一个问题就是各个互联网大厂一般都会有专门的部门开发专用的框架,所有发布出来的文章也是基于这些内部框架来写的,可能导致未进过大厂的同学很难更深入的理解也没法实际应用起来。另外很容易形成一个误区,就是开源的框架不经过二次封装是否可直接用到生产环境。这里笔者想说如果换成8、9年前答案是不可以,但现在随着
DDD毕竟是一个指导方法,想落地扎根还是需要很多尝试的,笔者整理了一下在部门内践行推广之初的复盘小结,这可能是多数团队在推广DDD时都会遇到的问题,希望能对大家有所帮助。DDD在部门进行两次尝试,一次是PPT培训,另外一次是一个新系统领域分析的事件风暴。现把两次尝试的过程做一个小结,内容仅供参考,大家共同讨论分享。下面分别从目的、过程、总结反思几个方面描述下这两次实践过程。实践一:DDD初探培训实
单用一篇文章很难把这个主题描述的清楚,但为了系列的完整性,笔者会围绕DDD中所介绍的内容做下初步总结,使读者有一个连续性。一、概述现在不是局部解决问题的时代了要运用新的技术创造新的效率提升,需要整个商业链条一起前进。需要以系统或生态的角度来考虑问题,而不能回到点到点的突破层面。基于以上背景慢慢的会衍生出新的岗位和角色。技术层面也驱于两级化发展,初级开发越来越倾向于工具的使用,高级研发越来越需要更全
本章围绕两个主题展开,会话管理和事务的处理(数据处理)流程,目的是了解下zk的CS模式是如何运转的。一、服务端启动详细的启动过程可参考https://blog.51cto.com/arch/5363898 文章中的描述,那么服务端启动后主要要做哪些工作呢,主要有以下三个:设置默认Watcher;设置Zookeeper服务器地址列表;创建ClientCnxn;二、会话2.1、创建会话创建的流
本节所涉及的内容多数都可以由zoo.cfg文件来配置一、内存数据Zookeeper的数据模型是树结构,Zookeeper会定时将数据存储到磁盘上,通过zoo.cfg文件来配置。在内存中存储了整棵树的内容,包括所有的节点路径、节点数据、ACL信息。这也是zk性能比较好的一个原因。1.1、DataTreeDataTree是内存数据存储的核心,它是一个树结构代表了内存中一份完整的数据。DataTree不
一、节点Zookeeper的数据节点称为ZNode,ZNode是Zookeeper中数据的最小单元,每个ZNode都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,称为树,如下图所示:每个数据节点都是由生命周期的,类型不同则会不同的生命周期,节点类型可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL)、顺序节点(SEQUENTIAL)三大类,可以通过组合生成
Zookeeper是一个高可用的分布式数据管理和协调框架,并且能够很好的保证分布式环境中数据的一致性。在越来越多的分布式系统(Hadoop、HBase、Kafka)中,Zookeeper都作为核心组件使用。典型应用场景数据发布/订阅负载均衡命名服务分布式协调/通知集群管理Master选举分布式锁分布式队列数据发布/订阅数据发布/订阅系统,即配置中心。需要发布者将数据发布到Zookeeper的节点上
一、概述相比单体应用而言分布式应用(因系统的范围比较大,所以笔者习惯使用“应用”这个概念,下文同)具有分布性、对等性、并发性等特点。同样也需要解决缺少全局时钟、通信异常、脑裂(分区异常)、三态(成功、失败、超时)、节点故障等问题;其中最重要的就是数据一致性问题。分布式一致性一般分为强一致性、弱一致性和最终一致性三种模式,最常被应用的是弱一致性和最终一致性这两种模式(最终一致性是弱一致性的一种特例,
本章内容做为多线程的最后一章主要是聊一聊“锁”,在高并发情况下影响多线程程序的性能最大的一个因素可能就是锁了,包含锁的范围、锁的类型等等,所以说锁的掌握可以说尤为重要。不同的文章对锁的分类都不一样,本章中笔者由浅入深,先从概念开始后API实现这样的一个顺序来描述。本章内容过后,JVM专题的常用的基础知识基本全聊完了,如果后续时间允许的话笔者会新开一个专题,专门讲一个多线程的相关知识:)一、基础知识
本章内容比较简单,主要是对Thread的实现方式做下初步介绍,稍带着描述下相关方法的原理和使用场景。此节的内容也是开发同学能不能写出高质量线程程序的一个基础,同样也非常重要。一、基础知识还是按之前文档描述的习惯,用一张图来概念下本章的内容,如下图所示红框内描述所示:(理论基础请看上一章内容,线程协同主要是讲锁相关的知识的后续会做为第三节补充上):二、Thread基本方法线程的基本方法基本就是Obj
任何一套程序都少不了异常和日志,从纯技术编码的角度来讲处理起来并不复杂。但这两块编码的目的更多是围绕非正常情况来设计的,所以从业务和运维的角度来讲想处理好日志和异常其实并不简单。所有的团队设计异常和日志的初衷都是好的,但有些团队在落地执行时并不会达到所预想的目的,甚至是为了制定而制定,产生大量无用编码的同时无形中增加了开发同学的工作量,同时也会影响程序的性能和代码的可读性。异常的目的:记录程序中异
Copyright © 2005-2025 51CTO.COM 版权所有 京ICP证060544号