
Pytho爬虫之初职HTML页面
前言
在上一章节我们介绍了什么是爬虫,以及爬虫的用处。同时我们也介绍了在学习爬虫之前需要对网页的基本构成有一个大体认识。
为了帮助没有前端基础的童鞋能够更好的进入开发状态,这一章节将对网页的结构,以及涉及的html、css、js和http协议进行一个简单的介绍。
在开始学习之前建议大家安装chrome浏览器,当然其他浏览器也行,只不过chrome在这方面做的相对比较好,课程中也将基本使用chrome浏览器。
在chrome浏览器中,一般按F12快捷键能够进入开发者模式,查看当前页面的构成,这对于大家学习爬虫,使用爬虫大有益处。
HTML和超文本标记语言
如果我们曾经使用开发者模式打开网页的话,那么我们一定见过如下图所示的景象:

在图中标红的区域,我们能够看到大量以XXX开头和/XXX结尾的标签对(XXX代表一个字符串),例如div和/div。这些标签,我们称之为HTML 标签 (HTML tag)。
HTML 是用来描述网页的一种语言,全称是超文本标记语言 (Hyper Text Markup Language),HTML是它的英文缩写。而这些由尖括号包围的关键词,正是HTML标记语言的重要组成部分,类似于python中的def、class这些关键字。
HTML 标签通常是成对出现的,比如 div和/div,标签对中的第一个标签是开始标签,第二个标签是结束标签。
一个最简单的HTML标记语言的例子如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>你好,码上开始</p>
</body>
</html>
与 之间的文本描述网页,head 与 /head之间一般定义表头和一些元数据, 与 之间的文本是可见的页面内容,
与
之间的文本被显示为段落。 显示效果如下: 从上面最简单的例子我们可以看出,一个最简单的页面通常至少会有三个标签:一个是html代表这是一个html页面,一个head代表页面的一些元数据信息,一个body代表页面内容。 如果我们使用一些工具打开刚才的页面内容,比如pycharm或者notepad++,通常会提供一种折叠效果,如下图所示: 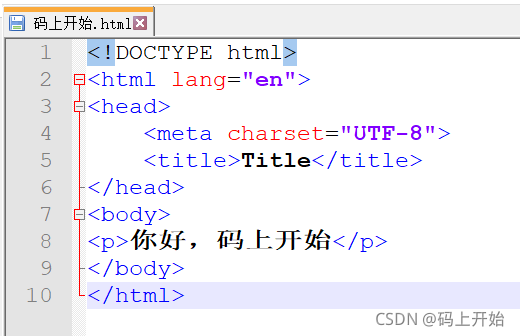 如果我们点击html标签进行折叠的话,我们发现最后只能显示一个元素,如下图所示: 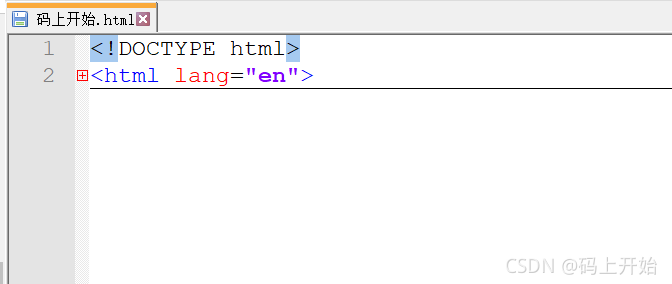 这显示的最后一个,我们称之为这个页面文档的根结点,其他的节点我们称之为这个根节点的子节点。这说法是不是有种似曾相识的感觉?对,在我们前面的数据结构章节我们对于树形结构就有类似的说法。 对于所有的网页页面文档,我们本质上可以看作一个树形结构,即DOM树。DOM树,原意为文档对象模型(Document Object Model,简称DOM),是W3C制定的标准接口规范,是一种处理HTML和XML文件的标准API。 DOM提供了对整个文档的访问模型,将文档作为一个树形结构,树的每个结点表示了一个HTML标签或标签内的文本项。DOM树结构精确地描述了HTML文档中标签间的相互关联性。将HTML或XML文档转化为DOM树的过程称为解析(parse)。 我们使用爬虫爬取网页,获取数据,本质上就是先获得这个页面的DOM树,然后通过解析这棵DOM树来获取我们想要的数据。
css层叠样式表
上面给出的最简单的例子显示的页面内容形式过于简单,字体的大小、颜色、位置等信息都没有设置。在HTML标记语言中,一般是采用一种叫做CSS层叠样式表的东西给它添加美化效果,如下图所示:

对于css,我们一般比较关注class这个属性,一般我们叫做类属性。通过这个属性,我们能够根据一个标签的css样式很快的访问到这个标签。
关于css的语法细节,这里就不多赘述,有兴趣的可以登录W3C school自行进行学习。
JavaScript简介
对于一个静态的网页,为了让它显得有趣,会加入各种动态效果,比如页面弹窗、图片切换等,这种动态效果一般是借助一种叫做JavaScript的语言进行实现的。既然页面使用了这种语言,那么了解它,对于抓取页面信息就会锦上添花。
JavaScript 本身跟python一样,也是一种弱类型语言。它可以收集用户的跟踪数据,不需要重载页面直接提交表单,在页面嵌入多媒体文件,甚至运行网页游戏。那些看起来非常简单的页面背后通常使用了许多 JavaScript 文件。
你可以在网页源代码的
一般现在很少有人会使用原始的JavaScript语法,一般会借助第三方库,比如JQuery、Node.js和Vue.js,进行二次开发。
关于js的语法细节,这里就不多赘述,有兴趣的可以登录W3C school自行进行学习。
http协议
在上一章介绍过,在web网页间的通信,采用的是http协议或者https协议。https协议除了多了一个加密的功能之外,其他的基本跟http差不多。这里就不分开介绍,有兴趣的可以自行百度学习。
一个http协议通常有三部分构成:第一部分是方法、url和版本信息,典型的方法有get、post、delete、put等;第二部分是头部信息,一般定义的是主机信息、连接状态、内容编码和内容长度等;第三部分是内容,所谓内容,就是请求的信息和响应的信息,不同方法的内部部分略有差异。有兴趣的,可以进一步自行学习。

了解http协议有什么用呢?正如我们在前面讲过,有爬虫就有反爬虫机制。那反爬虫是实现呢?基本上是从http协议头部信息的角度入手,识别究竟是人操作还是脚本自动操作。
因此对http协议进行了解,就可以反反爬虫,扩大自己的爬取数据范围。
前面讲了那么多,在文章的末尾,我们就以百度的首页为例,看下html标签、css、js和http协议在实际中是什么样的。
页面部分:

http协议部分

当然,在实际中如果要对http协议进行分析,一般不赞成使用chrome去查看,这种只能用于查看简单的ajax请求报文信息。
如果想要对http协议报文进行深入分析,建议使用第三方专业的抓包工具,比如fiddler、wireshark、burysuit等。不仅更专业,还会有额外的附加功能,是日常网络管理必备工具之一。
如果对软件测试、接口测试、自动化测试、技术同行、持续集成、面试经验交流。感兴趣可以进到893694563,群内会有不定期的分享测试资料。
如果文章对你有帮助,麻烦伸出发财小手点个赞,感谢您的支持,你的点赞是我持续更新的动力。

















